Big data is not new. Its origin can be traced back to the concept of ‘information explosion’ which was identified first in 1941. Ever since, there has been a big challenge – developing a practical method handle large volume, wide variety, and fast moving data. Without a suitable tool that can simplify the analysis and manipulation of enormous volumes of data, the organization’s ability to generate knowledge from the data is limited.
Currently, the increasing interest and growth in data science, analytics, and big data can be attributed to the arrival of effective tools for handling big data. Hadoop is a significant piece of any corporation’s big data strategy.
Hadoop was first developed in 2005, to serve as open source framework for dependable and scalable distributed computing. It can store and process large data sets efficiently and cost-effectively using its commodity hardware.
The ability to execute batch processes in parallel makes Hadoop an efficient big data tool. Moving your data across the network to the central processing node is not necessary. Instead, this tool enables you to solve big problems by dividing them into small milestones that can be completed independently and then bring the results together to obtain a final answer.
The commodity hardware makes Hadoop a cost-effective big data tool. The huge data sets can be broken up and kept in local disks of an ordinary size. Any failure is handled using software solutions, rather than servers that tend to be very expensive.
Components of Hadoop
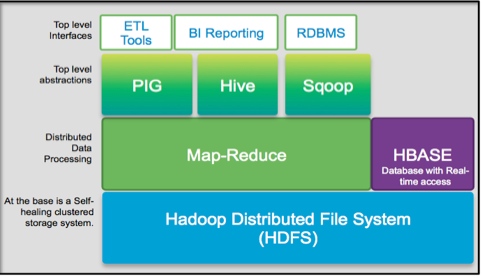
There is a lot of data that web generates daily. To make the data searching process easier, Google had to index the data, but maintaining the index was daunting. Therefore, Google created MapReduce style of data processing to ease the difficulties encountered in indexing the data. It is worth noting that MapReduce programming utilizes two key functions – a map job to convert a data set into value/key pairs and reduce function that puts the outputs together to form a single result. This approach was adopted by Hadoop developers.
Here are the components of Hadoop.
1. MapReduce
MapReduce supports the distributed calculation of projects by dividing the problem into small milestones and later combine the outcomes to obtain a final answer.
2. HDFS
HDFS simply means Hadoop Distributed File System and can support the distributed storage of huge data files. It splits up the files and distributes it to all the nodes in the cluster by creating multiple copies of data for reliability and redundancy purposes. The HDfs access the data automatically from any of the created copies if the node fails.
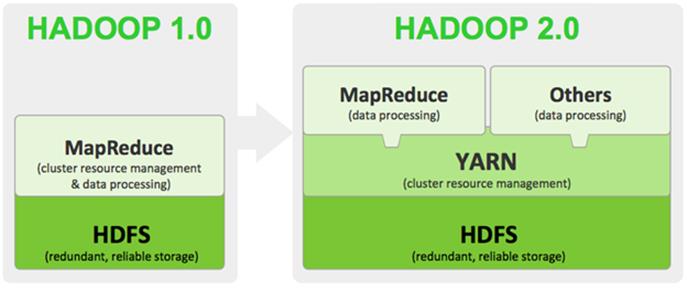
3. YARN (Yet Another Resource Negotiator)
YARN was introduced in Hadoop 2.0 and it manages the Hadoop cluster’s computing resources as well as providing scheduling services. With the help of YARN, Hadoop can support other frameworks apart from MapReduce. With that, it is clear that Hadoop’s functionality is extended, and it can support real-time and interactive computations on a streaming data and perform batch job processing.
4. Hadoop common
This is the Hadoop’s library that hosts the other three components.
Note that Hadoop can run on one machine, and this is useful especially when experimenting though it also runs in cluster configurations.
Benefits of using Hadoop
Hadoop has so many benefits when it comes to solving big data complex equations. Here are some of these advantages.
It is a cost-effective tool as its commodity hardware can be used to achieve availability and fault tolerant computing as well as large-capacity storage.
It solves problems efficiently as it uses its multiple nodes which perform different tasks on the same problem simultaneously. It also performs computations on the storage nodes, reducing delays as the data is moved from storage nodes to compute nodes. Also, since data is not moved between servers, the huge volume of the data does not overload the network.
You can extend the Hadoop because servers can be added dynamically hence, increasing its storage and compute capacities.
The Hadoop is highly flexible as it can be used to run other applications though it is mostly used with the MapReduce. Its flexibility can be attributed to its ability to handle any data type – structured or unstructured.
All these benefits, especially flexibility does not imply that Hadoop is an ideal solution to every data problem. You can use traditional methods to solve problems with small data sets. Also, note that the HDFS were designed to support the write-once-read-many tasks and are not ideal for applications that need to update data.
Typical use cases
Organizations use Hadoop in various business domains. Here are ten problems that are suited for its analysis.
- Analyzing customer churns
- Recommendation engine
- Ad targeting
- Network data analysis to predict the future
- Analysis of transactions at point of sale
- Risk modeling
- Data sandbox
- Threat analysis
- Trade surveillance
- Search quality
The Business requiremnts determines these Hadoop use cases, but data sandbox is one of the several technical reasons you need to use Hadoop.
Despite the increased use of Hadoop, there are some qualms about its future. First, the platform a bit complex and this makes it difficult for the business to get started. The rise of the spark has made some to perceive Hadoop as the future of Big Data. Nevertheless, understanding Hadoop is crucial for organizations that wish to get value out of their data warehouses, databases and data lakes.